How Trankit works
Note: The best way to understand how Trankit works is to look at our technical paper, which is available at: https://arxiv.org/pdf/2101.03289.pdf
In this section, we briefly present the most important details of the technologies used by Trankit.
Natural Language Processing (NLP) pipelines of current state-of-the-art multilingual NLP Toolkits such as UDPipe (Straka, 2018) and Stanza (Qi et al., 2020) are trained separately and do not share any component, especially the embedding layers that account for most of the model size. This makes their memory usage grow aggressively as pipelines for more languages are simultaneously needed and loaded into the memory. Most importantly, these toolkits have not explored contextualized embeddings from pretrained transformer-based language models that have the potentials to significantly improve the performance of the NLP tasks, as demonstrated in many prior works (Devlin et al., 2018, Liu et al., 2019b, Conneau et al., 2020). This motivates us to develop Trankit that can overcome such limitations.
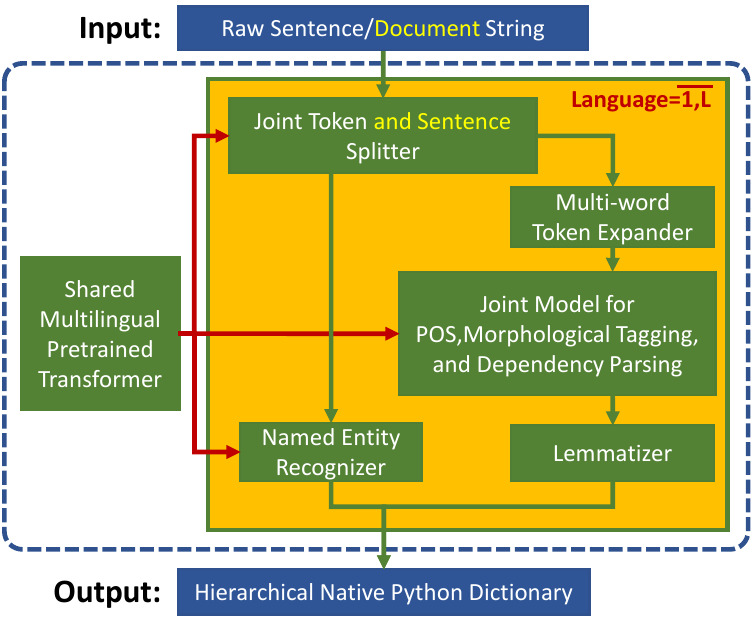
Overall architecture of Trankit. Among the five models, three (i.e., joint token and sentence splitter; joint model for part-of-speech tagging, morphological tagging, and dependency parsing; and named entity recognizer) in Trankit are transformer-based. They all share a single multilingual pretrained transformer.
First, we utilize the state-of-the-art multilingual pretrained transformer XLM-Roberta (Conneau et al., 2020) to build three components: the joint token and sentence splitter; the joint model for part-of-speech, morphological tagging, and dependency parsing; and the named entity recognizer (See the figure above). As a result, our system advances state-of-theart performance for sentence segmentation, part-of-speech (POS) tagging, morphological feature tagging, and dependency parsing while achieving competitive or better performance for tokenization, multi-word token expansion, and lemmatizatio over the 90 treebanks.
Second, we simultaneously solve the problem of loading pipelines for many languages into the memory and the problem of the transformer size with our novel plug-and-play mechanism with Adapters (Pfeiffer et al., 2020a, Pfeiffer et al., 2020b). In particular, a set of adapters (for transfomer layers) and task-specific weights (for final predictions) are created for each transformer-based component for each language while only one single large multilingual pretrained transformer is shared across components and languages. During training, the shared pretrained transformer is fixed while only the adapters and task-specific weights are updated. At inference time, depending on the language of the input text and the current active component, the corresponding trained adapter and task-specific weights are activated and plugged into the pipeline to process the input. This mechanism not only solves the memory problem but also substantially reduces the training time.